图片来源: https://bytebytego.com
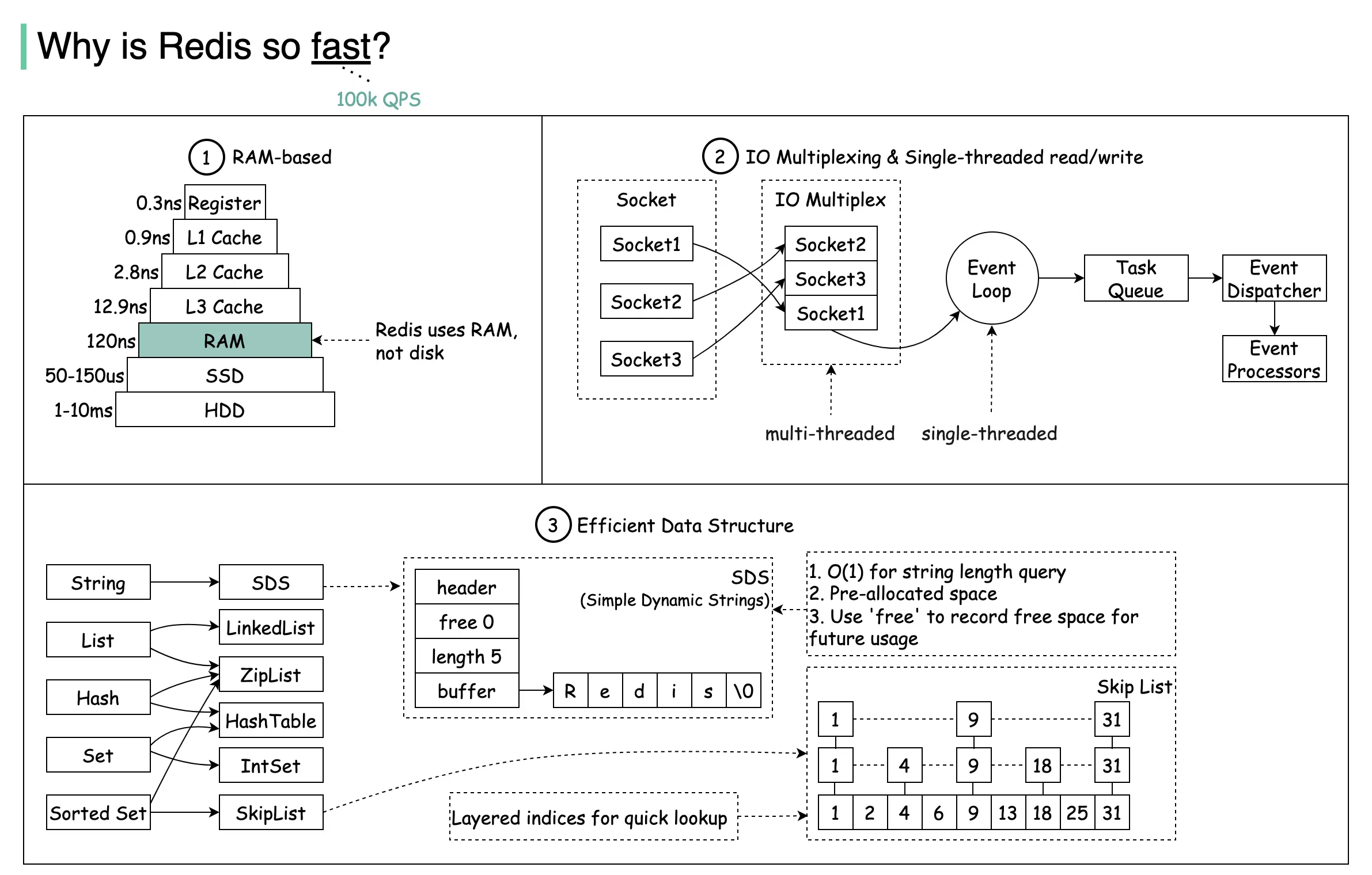
一、基于内存(RAM-based)
1. Redis 使用内存而非磁盘
- Redis 的数据主要存储在 RAM(内存) 中
- 避免了磁盘 IO 带来的巨大延迟
2. 不同存储介质的延迟对比(近似值)
| 存储层级 | 延迟 |
|---|---|
| CPU Register | ~0.3 ns |
| L1 Cache | ~0.9 ns |
| L2 Cache | ~2.8 ns |
| L3 Cache | ~12.9 ns |
| RAM | ~120 ns |
| SSD | 50–150 μs |
| HDD | 1–10 ms |
内存访问速度比 SSD 快 数百倍,比 HDD 快 数万倍,这是 Redis 高性能的根本原因
二、IO 多路复用 + 单线程模型
1. IO 多路复用(IO Multiplexing)
- Redis 使用 IO 多路复用机制(如
epoll / kqueue / select) - 一个线程即可同时监听 大量 Socket 连接
示意:
Socket1
Socket2 ──► IO Multiplex
Socket3
2. 单线程读写模型
Redis 的 核心读写逻辑是单线程的
优点:
- 无锁竞争
- 无线程切换开销
- 执行路径极短、可预测
3. Redis 事件处理流程
IO Multiplex
↓
Event Loop(单线程)
↓
Task Queue
↓
Event Dispatcher
↓
Event Processor
Redis 用单线程 + 非阻塞 IO 的方式,实现了“看起来像并发,实际是串行执行”
三、高效的数据结构设计
Redis 并不是简单的 KV 存储,而是为性能深度定制了数据结构。
1. String —— SDS(Simple Dynamic String)
SDS 的核心特性
- O(1) 获取字符串长度(不需要遍历)
- 预分配空间,减少频繁内存申请
- 使用
free字段记录剩余空间,便于扩容
SDS 结构示意
| header | len = 5 | free = 0 | buffer = "Redis" |
对比 C 字符串:
strlen是 O(n),SDS 是 O(1)
2. List(列表)
可能使用的数据结构:
- LinkedList
- Ziplist(紧凑存储,节省内存)
3. Hash(哈希)
使用:
- HashTable
- Ziplist(小对象时)
4. Set(集合)
- 使用 IntSet 存储整数集合
- 内存占用小,查询速度快
5. Sorted Set(有序集合)
底层结构:
- SkipList(跳表) + HashTable
SkipList 的优势
- 多层索引结构,加速查找
- 平均时间复杂度:O(log n)
示意:
Level 3: 1 ----------- 18 ----------- 31
Level 2: 1 ---- 9 ---- 18 ---- 31
Level 1: 1 - 4 - 9 - 18 - 31
跳表比平衡树实现简单,更适合 Redis 的高性能场景